Combining user and database perspective for solving keyword
queries over relational databases
Mengkombinasikan persepktif pengguna dan basis data untuk menyelesaikan
masalah deretan kata kunci pada basis data relasional.
Oleh :
Sonia
Bargamaschi, Francesco Guerra, Matteo Interlandi, Raquel Trillo-Lado, Yannis Velegrakis
DIEF –
University of Modena and Reggio Emilia, Italy
UCLA –
University of California, Los Angeles, USA
DIIS –
University of Zaragoza, Spain
DISI –
University of Trento, Italy
Dalam relational database model, sebuah database adalah kumpulan relasi yang saling terhubung satu sama lainnya. Relasi adalah istilah dalam relational database, tapi kita lebih familiar jika menyebutnya sebagai tabel. Selayaknya tabel yang memiliki kolom dan baris, dalam relational database, kolom (column) disebut attribute, sedangkan baris (row) disebut tuple. Hal ini hanya sekedar penamaan, dan agar lebih gampang, kita hanya akan menggunakan istilah tabel, kolom dan baris dalam tutorial ini, namun jika anda menemui istilah relation, attribut dan tuple, itu hanya penamaan lain dari tabel, kolom, dan baris.
Candidate Key (Kunci Kandidat)
Database dalam relational database dapat diserhanakan sebagai sekumpulan tabel yang saling terhubung. Setiap baris dari dalam tabel setidaknya harus memiliki sebuah kolom yang unik. Unik disini maksudnya tidak boleh sama. Contohnya, dalam tabel 4.1 : tabel data_mahasiswa, kolom NIM (Nomor Induk Mahasiswa) akan menjadi kandidat yang bagus, karena tidak mungkin ada 2 mahasiswa yang memiliki NIM yang sama. NIM disini disebut juga dengan Candidate Key (Kunci Kandidat). Candidate Key adalah satu atau beberapa kolom dalam tabel yang bisa mengidentifikasi tiap baris dari tabel tersebut.
Abstrak
Selama sepuluh tahun, kata kunci yang dicari pada
data relasional telah mengundang perhatian. Pendekatan yang mungkin dilakukan
untuk mengendalikan isu ini untuk mentranformasikan deretan kata kunci menjadi
satu atau lebih deretan SQL yang akan dieksekusi dengan DBMS relasional.
Menemukan deretan tersebut merupakan suatu tantangan saat informasi yang
disajikan dan juga tersedia bersilangan dan berbeda antara atribut dan
spesifikasinya. Maksudanya adalah ini tidak hanya membutuhan elemen skema dari
data dimana itu di simpan, tetapi juga untuk menemukan elemen ini saling
berhubungan. Semua pendekatan yang telah dilakukan, akan memberikan solusi
monolitik. Pada bagian ini, kita membagi menjadi 3 bagian : pertama dengan
melihat dari sisi pandang pengguna, masuk ke dalam akun pengguna saat mereka
menyusun deretan kata kunci. Langkah kedua berdasarkan perspektif basis data. Berdasarkan
bagaimana data disajikan pada skema basis data. Pada langkah terakhir memadukan
antara proses pertama dan kedua. Kita menyajikan teori dibalik pendekatan kami
dan mengimplementasikan ke dalam sistem yang disebut QUEST (Query generator for
structures sources). Yang mana telah dites
untuk menunjukkan efektifitas dan efisiensi dari pendekatan yang kita
lakukan. Lebih lanjut lagi, dilaporkan pada luaran dari jumlah percobaan yang
telah dilakukan.
1.
Pendahuluan
pencarian kata kunci telah menjadi standar
de-facto untuk mencari di web. sumber data terstruktur mengandung sejumlah
besar informasi yang signifikan akan tersedia untuk query. Biasanya, antarmuka
permintaan terdiri dari bentuk web yang memungkinkan query yang telah
ditetapkan untuk berpose di isinya. Selain itu, mesin pencari web mengindeks
konten sumber-sumber (yang disebut web tersembunyi) melalui hasil query bentuk
web ini, melihat teks sebagai gratis. Terlepas dari kenyataan bahwa ini
membatasi jenis data yang dapat dicari, banyak informasi semantik yang
disediakan oleh struktur data, misalnya, skema, pada dasarnya hilang. Hal ini
melahirkan minat khusus dalam mendukung pencarian kata kunci lebih database
terstruktur [1] dengan cara yang sama efektifnya dengan yang ditawarkan pada
data teks dan pada saat yang sama mengeksploitasi sebanyak mungkin struktur
data yang database menyediakan. Banyak pendekatan mengeksploitasi teks lengkap
fungsi pencarian native diimplementasikan dalam DBMS, seperti mengandung fungsi
di SQL server dan fungsi pertandingan melawan dalam MySQL, untuk menemukan
atribut dari database yang berisi query kata kunci pada saat run-time.
Kemudian, mereka membangun jawaban ditetapkan dengan menggabungkan tuple yang
mengandung kata kunci permintaan yang berbeda dan memilih orang-orang kombinasi
yang dianggap paling mungkin apa yang pengguna cari [12/02] pendekatan
.Allthese biasanya heuristik berbasis, tanpa spesifikasi yang jelas dari
langkah-langkah yang diperlukan untuk menjawab query.Inthiswork kata kunci,
weadvocatethatthereisaneedfora pendekatan yang lebih berprinsip untuk kata
kunci pencarian data terstruktur; khususnya, kami percaya bahwa pencarian kata
kunci pada sumber terstruktur membutuhkan tiga langkah fundamental. Ada karya
terdiri dari baik solusi monolitik end-to-end yang tidak memberikan perbedaan
yang jelas dari ketiga langkah ini, atau berfokus pada hanya beberapa dari
mereka, mengingat beberapa implementasi langsung dari sisa. Tiga langkah dasar
kita dipertimbangkan adalah pertama yang sesuai dengan kata kunci ke struktur
database, maka untuk menemukan cara-cara struktur cocok dapat dikombinasikan,
dan akhirnya untuk memilih pertandingan terbaik dan kombinasi sehingga struktur
database diidentifikasi mewakili apa yang pengguna dalam pikiran untuk
menemukan ketika merumuskan query kata kunci. Langkah pertama difokuskan pada
mencoba untuk menangkap makna dari kata kunci dalam query seperti yang dipahami
oleh pengguna, dan mengungkapkannya dalam hal istilah database, yaitu, struktur
metadata dari database. Dalam beberapa hal, ia menyediakan perspektif pengguna
dari query kata kunci dan ia melakukannya dengan menyediakan pemetaan kata
kunci ke dalam istilah basis data. Langkah ini disebut sebagai langkah analisis
maju karena dimulai dari kata kunci dan bergerak ke arah database. Langkah
kedua mencoba untuk menangkap makna dari kata kunci karena mereka dapat
dipahami dari sudut pandang para insinyur Data yang merancang organisasi
database, dan mengungkapkannya dalam satuan semantis koheren struktur database
yang berisi
gambar dari kata kunci yang ditentukan oleh
langkah pertama. Jadi, dalam arti, ia menyediakan perspektif database query
kata kunci dan ia melakukannya dengan menyediakan hubungan antara gambar dari
kata kunci. Tugas ini disebut sebagai langkah analisis mundur karena dimulai
dari struktur database dan bergerak menuju kunci permintaan melalui gambar
mereka. Langkah ketiga memberikan peringkat dari unit yang koheren dari
struktur database yang langkah kedua yang diproduksi setelah memilih mereka
yang lebih menjanjikan, yaitu, mereka yang semantik lebih mungkin mengungkapkan
apa yang pengguna dalam pikiran saat itu merumuskan permintaan kata kunci.
Dalam karya-karya kami
sebelumnya kami telah mempelajari aspek yang berbeda dari masalah pencarian
kata kunci lebih database relasional. The KEYMANTIC [13,14] sistem terfokus
pada langkah pertama. Ini memberikan solusi berdasarkan model yang cocok graf
bipartit di mana kata kunci pengguna yang cocok untuk unsur skema database
dengan menggunakan ekstensi dari algoritma Hungaria. KEYMANTIC adalah salah
satu solusi pertama yang berhubungan dengan masalah query database struktural
melalui kata kunci ketika tidak ada akses sebelum isi database untuk membangun
indeks apapun, sehingga, mengandalkan informasi semantik dari database
meta-data. Fitur ini dari KEYMANTIC membuatnya sangat sesuai untuk pencarian
berdasarkan kata kunci pada sistem database federasi dan
untuk menjelajahi sumber data di web tersembunyi.
KEYRY [15,16] diperpanjang KEYMANTIC dengan menyediakan kerangka kerja
probabilistik, berdasarkan HMM, untuk mencocokkan kata kunci ke dalam elemen
skema database. Kedua karya berurusan dengan langkah pertama proses yang
dijelaskan sebelumnya, yaitu, langkah perspektif pengguna.
Pengalaman kami dengan sistem ini membuat jelas
bahwa ini tidak cukup untuk solusi lengkap. Sistem ini adalah motivasi untuk
kerangka berprinsip, holistik dan terpadu disajikan dalam pekerjaan ini.
Kontribusi utama dari kertas saat ini sebagai berikut: (i) kami memperkenalkan
model 3-langkah mendasar untuk masalah pencarian kata kunci lebih database
terstruktur; (Ii) kita mengembangkan dua implementasi yang berbeda dari langkah
pertama, salah satu yang mengeksploitasi aturan heuristik dan satu yang
didasarkan pada mesin
teknik pembelajaran. Kedua bertujuan menemukan
yang sesuai spesifikasi Hidden Markov Model untuk menghasilkan pemetaan yang
tepat dari kata kunci kueri ke dalam struktur database; (Iii) kita
mendefinisikan sebuah implementasi dari langkah kedua berdasarkan Steiner Pohon
penemuan yang mengeksploitasi saling jarak berdasarkan informasi yang berat
tepi dan yang bekerja di tingkat skema bukannya tingkat contoh; (Iv) kami
menyediakan kerangka kerja probabilistik didirikan pada Shafer Teori Dempster
yang mampu menggabungkan dua langkah pertama dan modalitas dalam cara yang
memungkinkan sistem untuk segera beradaptasi dengan kondisi kerja yang berbeda
dengan memilih kombinasi terbaik antara mereka; (V) kami menerapkan semua hal
di atas dalam sistem yang disebut QUEST (Query generator untuk sumber
terstruktur) [17] dan memberikan rincian pelaksanaannya; dan akhirnya (vi) kita
melakukan serangkaian luas eksperimen yang menawarkan pemahaman yang mendalam
dari seluruh proses, efektivitas dan efficiency.The sisa kertas adalah sebagai
berikut. Pertama, berprinsip pendekatan 3-langkah diperkenalkan dan kerangka
yang diusulkan kami secara formal didefinisikan dalam Bagian 2. Pelaksanaan
masing-masing dari tiga langkah di QUEST prototipe kami dikembangkan berikut
dalam Bagian 3. Hubungan kerangka kita dengan karya-karya terkait bersama kami karya-karya
sebelumnya sendiri pada topik dijelaskan dalam Bagian 4.Finally, evaluasi
eksperimental theresultsofour luas dibahas dalam Bagian 5.
2.
Bagian
3 Langkah Bingkai Kerja
Sebagai model data untuk database terstruktur
kita asumsikan model relasional, namun kerangka dapat dengan mudah diperluas
untuk model terstruktur lain juga. Kami berasumsi set A tak terbatas nama
atribut, R nama relasi, dan V domain nilai. Sebuah tuple adalah himpunan
berhingga dari atribut pasangan nama-nilai <A1: v1; A2: v2; ...; Sebuah:
vn> mana Ai A A, vi A V i dengan V i A V, untuk i ¼ 1 ... n, dan Ai sebuah
Aj jika i a j. Skema tupel adalah <A1: V 1; A2: V 2; ...; Sebuah: V n> dan
arity adalah jumlah n. Domain Vi disebut sebagai domain dari atribut Ai dan
akan dinyatakan sebagai DomðAi Þ, untuk i ¼ 1 ... n. Suatu relasi contoh adalah
himpunan berhingga dari tupel, semua dengan skema yang sama. Skema hubungan
contoh adalah skema umum dari tupel dan kardinalitas jumlah tupel terdiri dari.
Suatu relasi adalah sepasang <R; IR>, di mana R A R, disebut dengan nama
relasi, dan IR adalah hubungan misalnya. Skema dari relasi <R; IR> adalah
skema hubungan contoh nya, dan akan dinyatakan sebagai RðA1: V 1; ...; Sebuah:
V n Þ, di mana <A1: V 1; ...; Sebuah: V n> adalah skema dari IR hubungan
misalnya. Dalam apa yang berikut, saat- pernah ada risiko kebingungan, nama R
akan digunakan untuk merujuk pada seluruh relasi <R; IR>. Selain itu,
sinyal akan adanya domain akan dihilangkan mengarah ke ekspresi fied simpli-
dari skema relasi sebagai RðA1; A2; ...; Sebuah Þ. Akhirnya, notasi JRJ akan
menyatakan arity dari relasi
R dan JiR j kardinalitas relasi contoh nya [18].
 |
| Gambar 1. Alur relational Database |
Konfigurasi
semantik ambigu. Mereka mungkin menggambarkan arti dari kata kunci dalam hal
database, tapi mereka tidak menjelaskan bagaimana istilah yang terhubung untuk
membentuk sebuah unit semantik yang koheren yang memberikan makna semantik
untuk query kata kunci seluruh. Koneksi ini harus berdasarkan cara gambar dari
kata kunci query (seperti yang diungkapkan melalui konfigurasi) yang terhubung
dalam database.
Ada
biasanya dua cara utama istilah database yang terhubung. Salah satunya adalah
struktur, yaitu, cara administrator data yang telah dipilih untuk model data
dalam repositori. Misalnya, dua atribut ditempatkan dalam hubungan yang sama
ketika desainer data yang percaya bahwa mereka menggambarkan dua sifat yang
berbeda dari konsep bahwa hubungan adalah tentang, dan akibatnya mereka harus
dihubungkan. Cara lain adalah penggunaan kendala skema, di kendala referensial
tertentu seperti / hubungan kunci kunci asing. Hubungan ini menggambarkan cara
di mana struktur dalam hubungan yang berbeda dapat dikaitkan dengan membentuk
bergabung jalur. Kita merujuk pada cara bahwa istilah database yang berfungsi
sebagai gambar dari kata kunci permintaan dapat asosiasi sebagai pretations
internasional karena mereka tidak hanya menunjukkan apa setiap kata kunci
mewakili, tetapi mereka juga memberikan interpretasi dari permintaan kata kunci
seluruh segi struktur database dan kendala semantik.
Untuk
lebih formal menentukan interpretasi kami memperkenalkan gagasan grafik basis
data.
Contoh
2.4. Salah satu aturan heuristik yang umum diadopsi untuk peringkat
interpretasi didasarkan pada jumlah tepi yang terlibat. Interpretasi dengan
lebih ujung dapat mencakup tepi ekstra yang tidak dibenarkan oleh setiap
istilah dalam permintaan pengguna dan berhubungan hal-hal yang semantik jauh.
Di antara dua interpretasi [A.1] dan [A.2] disebutkan dalam Contoh 2.3, [A.2]
memiliki lebih ujung. Meskipun ada kemungkinan untuk [A.2] untuk benar-benar
mewakili semantik bahwa pengguna mencari dengan permintaan kata kunci yang
disediakan, itu kurang mungkin karena [A.2] melibatkan unsur-unsur yang secara
semantis lanjut dari sudut pandang Database desainer.
2.3. Memproduksi penjelasan
Karena
data disimpan dalam menyimpan data relasional, untuk mengambil unsur-unsur
kepentingan diperlukan untuk menghasilkan sejumlah query SQL. Kami mengacu pada
pertanyaan ini sebagai penjelasan karena mereka benar-benar menggambarkan satu
set data yang akan diambil sebagai tanggapan atas permintaan kata kunci yang
disediakan oleh pengguna, dan dalam arti "menjelaskan" apa query bisa
benar-benar berarti. Bagaimana penjelasan dihasilkan adalah masalah
implementasi khusus. Namun, yang penting adalah bahwa permintaan sql akhir
menghormati konfigurasi, yaitu, memastikan bahwa gambar dari kata kunci sebagai
istilah basis data yang hadir dalam query dan istilah ini terkait dengan cara
bahwa interpretasi menentukan.
Tentu,
tidak semua penjelasan sama-sama mungkin untuk mewakili maksud bahwa pengguna
dalam pikiran ketika merumuskan query. Kemungkinan bahwa penjelasan sebenarnya
mewakili maksud tersebut didasarkan pada tingkat yang baik konfigurasi dan
interpretasi yang diyakini mewakili apa yang pengguna dalam pikiran. Ini
berarti bahwa untuk membuat daftar peringkat yang paling menjanjikan
penjelasan
calon, salah satu kebutuhan pertama yang membuat daftar peringkat interpretasi
yang memperhitungkan tidak hanya peringkat interpretasi yang dihasilkan oleh
langkah analisis mundur, tetapi juga ranking dari figurasi con- dari mana
mereka berasal, seperti yang dihasilkan oleh analisis maju langkah. Ini mungkin
kasus misalnya, bahwa interpretasi peringkat sangat tinggi dalam daftar yang
dihasilkan oleh langkah kedua, tetapi konfigurasi yang interpretasi berasal
sangat rendah di peringkat konfigurasi yang dihasilkan oleh langkah pertama.
1. Kerangka pelaksanaan
Kami
telah terwujud kerangka kerja dijelaskan sebelumnya menjadi sistem yang disebut
QUEST. Sistem ini dapat digunakan sebagai add-on yang beroperasi di atas sistem
database. Sebelum operasi, QUEST perlu mengetahui beberapa informasi meta-data
tentang database. The meta-data informasi tion terdiri dari istilah database
samping kendala esensial referen-. Hal ini dilakukan dalam langkah
pre-processing dengan mengakses tabel database katalog. Hal ini juga perlu
akses ke indeks teks lengkap atas semua atribut basis data. Tentu saja, ada
kasus di mana akses tersebut tidak mungkin. Salah satu kasus tersebut adalah
satu di mana sumber data adalah bagian dari sistem integrasi sumber independen.
Biasanya sumber-sumber ini tidak memungkinkan akses penuh tidak terbatas ke
konten mereka, tapi hanya akses ke bagian-bagian tertentu melalui antarmuka
dikendalikan con. Dalam kasus ini beberapa informasi parsial dapat diperoleh
dari pengguna atau dengan menganalisis antarmuka yang database menyediakan.
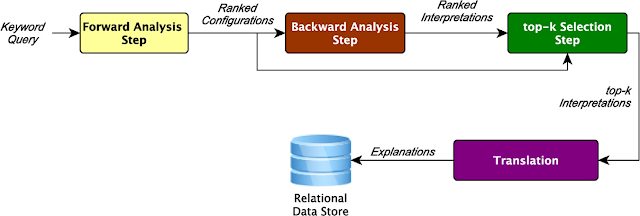
Proses
implementasi kerangka kerja keseluruhan Menyala didemonstrasikan pada Gambar.
5. Seperti dapat dilihat, untuk analisis ke depan ada dua implementasi yang
berbeda yang berjalan di paralel dan pada akhir hasil mereka digabung menjadi
satu set konfigurasi. Konfigurasi yang diberikan kepada back- pelaksanaan
bangsal langkah, yang mengambil satu per satu dan menghasilkan satu set
kemungkinan interpretasi. Semua interpretasi yang dihasilkan kemudian peringkat
menurut kriteria seleksi dan daftar peringkat disediakan untuk modul peringkat.
Yang terakhir menggabungkan interpretasi peringkat dengan konfigurasi peringkat
untuk menghasilkan satu set peringkat baru dari interpretasi dan pilih k atas.
Pada
akhirnya, masing-masing di atas-k diterjemahkan ke dalam query SQL. permintaan
kata kunci yang sangat samar. Mereka daftar datar dengan tidak ada hubungan
yang jelas antara kata kunci, sehingga banyak interpretasi yang berbeda yang
mungkin [29]. Kerangka kerja keseluruhan yang disajikan di sini didasarkan pada
asumsi tersembunyi yang semantik pengguna harus diingat ketika merumuskan query
yang dinyatakan sebagai permintaan SPJ. Namun, permintaan SPJ membentuk kelas
besar pertanyaan yang dapat memenuhi persyaratan aplikasi mayoritas atau
kehidupan nyata, kadang hal yang telah diakui [30]. Hampir semua permintaan
kata kunci menjawab teknik pada basis data- terstruktur mengikuti asumsi yang
sama [12/02]. Jelas, mungkin ada aplikasi yang membutuhkan query yang lebih
kompleks yang tidak bisa ditutupi oleh pendekatan kami, misalnya,
self-bergabung. Ini berfokus pada aplikasi tertentu, dan dapat ditangani
berdasarkan kasus per kasus. Misalnya, diri bergabung dapat diimplementasikan
dengan mempertimbangkan beberapa salinan jangka database yang sama pemodelan meja
yang diri bergabung dapat diterapkan. Sebagai contoh, grafik Gambar. 3 bisa
memiliki lebih dari satu node yang mewakili tabel Person, dan atribut yang
dimasukkan untuk memungkinkan diri bergabung di meja yang dianggap sebagai
penjelasan yang dihasilkan oleh sistem.
3.4. Menghasilkan penjelasan:
terjemahan
Salah
satu pendekatan untuk menghasilkan penjelasan dari interpretasi adalah untuk
mempertimbangkan semua tabel yang ada atribut atau domain atribut istilah
database dalam interpretasi, atau meja itu sendiri muncul sebagai istilah
database dalam penafsiran. Semua tabel ini merupakan bagian dari klausul mana.
Selanjutnya, untuk setiap hubungan antara istilah database termasuk dalam
konfigurasi, join kondisi antara meja masing-masing ditambahkan di mana klausa.
Pertanyaan menantang yang akan ditempatkan di pilih klausa, karena berbeda
dengan SQL atau bentuk terstruktur lainnya dari query, query kata kunci tidak
menentukan baik objek yang akan diambil maupun bentuk atau atribut mereka harus
memiliki. Dengan tidak adanya informasi tersebut, QUEST adalah kembali gambaran
yang lengkap dari struktur yang terlibat, yaitu, himpunan semua atribut yang
berhubungan dengan istilah database relasi yang terlibat dalam penafsiran.
Dengan kata lain, untuk QUEST penjelasan, yaitu, yang dihasilkan query SQL
final.
4.
pekerjaan Terkait
Selama
dekade terakhir, sejumlah besar pendekatan untuk memungkinkan pengguna untuk
mengakses data terstruktur dengan cara query kata kunci telah diusulkan.
Proposal ini dapat fied Classi menjadi dua kategori utama [1]: berbasis grafik
skema berbasis (alias hubungan-based) dan (alias tuple-based).
Berbasis
skema pendekatan model database yang akan bertanya sebagai grafik di mana node
mewakili hubungan dan atribut, dan tepi mewakili hubungan kapal key / kunci
asing atau keanggotaan. Dalam sistem semacam ini, permintaan kata kunci
biasanya dievaluasi dalam dua langkah. Pertama, query SQL yang dihasilkan untuk
menggambarkan arti yang diinginkan dari permintaan pengguna dalam hal basis
data. Selain itu, query peringkat dan dievaluasi berdasarkan relevansinya
(semantik dekat) untuk semantik permintaan pengguna diasumsikan. Kedua, query
SQL yang paling relevan dieksekusi untuk mengambil tupel dari database. Tujuan
utama di sini adalah untuk mengoptimalkan algoritma yang digunakan untuk
menghasilkan query SQL dan untuk memilih metrik yang tepat untuk evaluasi tuple
diambil oleh pertanyaan ini. Contoh sistem berikut pendekatan berbasis skema
mencakup DISCOVER [2], DBXplorer [3], MEMICU [5], dan SQAK [6].
Evaluasi
Eksperimental 5.
5.1.
Pengaturan eksperimen
Sumber
data. Kami mempekerjakan dua database yang sering digunakan dalam literatur
untuk evaluasi eksperimental: dial3 Senin-dan implementasi relasional DBLP.4
Bahkan jika database berisi sejumlah sebanding istilah basis data (227 dan 237
hal, masing-masing), mereka berbeda dalam ukuran dan jumlah koneksi antara
struktur data. DBLP memiliki struktur yang sederhana di mana tabel dapat
bergabung dalam sebagian besar kasus dengan jalur yang unik. Sebaliknya,
struktur Mondial adalah kompleks dan tabel sering bergabung dengan beberapa
jalur. Mengenai kasus, ukuran Senin-dial lebih dari dua kali lipat lebih kecil
dari DBLP. Sebagai contoh, "People" dan "inproceedings",
menggambarkan penulis dan kertas, yang pasti dua tabel DBLP terbesar dan memiliki
kedua kardinalitas hampir satu juta tupel. Selain itu, makalah terkait dengan
masing-masing penulis melalui tabel "author_inproceedings" yang
menghitung sekitar empat juta tupel. Tabel di Mondial lebih kecil: hanya satu
meja, "kota" berisi tiga ribu kasus, dan meja lainnya termasuk
sekitar (atau kurang) lima ratus tupel. Tabel 2 merangkum karakteristik utama
dari dataset.5 evaluasi
Fitur-fitur
ini membuat database yang dipilih di seberang
tingkat
dalam sistem evaluasi yang membandingkan ukuran kecil vs database ukuran besar
dan database datar vs database dengan struktur data yang kompleks. Akibatnya,
kami berharap bahwa dalam perhitungan konfigurasi (yaitu, pencocokan kata kunci
pengguna ke dalam istilah database) QUEST melakukan lebih baik di Mondial
daripada di DBLP, karena ukuran basis data.
5.6. Perbandingan dengan pendekatan
lain
Perbandingan
kinerja diperoleh pencarian kata kunci-pendekatan lebih database relasional
adalah tugas yang kompleks, terutama, karena tidak adanya patokan standar.
Pendekatan yang ada telah dievaluasi terhadap database yang berbeda dengan set
query yang berbeda. Fakta ini mencegah perbandingan langsung mereka berdasarkan
hasil eksperimen aslinya. Selain itu, dalam beberapa kasus, kerangka evaluasi
diadopsi tampaknya tidak memadai, terutama, karena kerja dari sejumlah kecil
pertanyaan diri menulis [41], yang mengarah ke hasil yang bias. Hanya
baru-baru, patokan [39] mengusulkan beberapa metrik dan query diatur untuk mengevaluasi
pendekatan terhadap tiga sumber data (Mondial, IMDB dan Wikipedia). Bahkan jika
benchmark merupakan langkah penting menuju evaluasi yang adil dari pendekatan
pencarian kata kunci, metrik diadopsi (presisi dan ingat dibandingkan dengan
standar emas, dan waktu yang diperlukan untuk mengembalikan hasil) tidak bisa
cocok bila diterapkan pada pencarian kata kunci berbasis skema sistem, seperti
QUEST, yang mengubah query kata kunci ke dalam query SQL. benchmark, pada
kenyataannya, menghitung efektivitas pendekatan dengan menganalisis hasil
(contoh) diambil dengan pertanyaan kunci tertentu sedangkan pendekatan
pencarian berbasis skema memberikan query SQL sebagai hasil [42]. Perhatikan
bahwa semua tupel yang dihasilkan dari query SQL yang sama memiliki intrinsik
skor yang sama, dan bahwa hasil yang sama dapat diperoleh dengan pertanyaan
yang berbeda.
6. Kesimpulan
Kami
telah disajikan QUEST, kerangka kerja untuk pencarian kata kunci lebih database
relasional yang membelah proses untuk memecahkan query kata kunci dalam tiga
langkah: maju, mundur dan kombinasi dari keduanya. Langkah maju menghasilkan
konfigurasi, yaitu, pemetaan kata kunci ke dalam istilah basis data.
Konfigurasi yang diturunkan mengikuti perspektif pengguna, yaitu,
memperhitungkan bagaimana query telah dirumuskan oleh pengguna. Interpretasi
langkah mundur dirumuskan dari konfigurasi diperoleh, yaitu, jalur bergabung
database struktur yang terlibat dalam konfigurasi. Ini dihitung tindak ing
perspektif basis data, yaitu, dengan mempertimbangkan bagaimana informasi
sebenarnya terfragmentasi di sejumlah tabel dalam database. Konfigurasi dan
interpretasi masing-masing digabungkan untuk membentuk sebuah jawaban untuk
query kata kunci dan dengan cara kerangka probabilistik yang memungkinkan pengguna
untuk menentukan tingkat ketidakpastian peringkat. QUEST benar-benar
disesuaikan dan mampu memberikan - sebagai hasil eksperimen menunjukkan - hasil
yang sangat akurat secara independen dari ukuran basis data, struktur com-
plexity, akses langsung ke contoh, dan ketersediaan fungsi pencarian teks
penuh.























